Everything’s coming up roses.
续上次的笔记
分享yolo-darknet神经网络训练全过程的配置经验
前言
由于本文中描述的yolo-darknet训练配置流程来源较多,而且训练配置时间为今年暑期,距离本文完稿时间较远,因此本文不可避免地会存在一定的失误和错漏。恳请发现问题的读者不吝赐教,通过首页的联系方式向作者提出宝贵意见。
数据集的标注、修改
数据集的采集来源以及采集方式属于项目内容,此处暂时不便叙述。对于采集得到的数据集,尤其是针对yolo-darknet的图片数据集,应当至少满足如下的要求:
- 文件名称中不应当出现中文
- 多次采集得到的文件应当分开命名前缀,否则存在同名文件覆盖的问题
- 最好是同一种后缀格式,例如jpg格式。后缀大写JPG和小写jpg,darknet不会认为是同一种文件类型而报错。另外,png格式比较灵活,可以强行改成jpg后缀且内容仍可以读取
本项目中除了采集了原始数据之外,也通过python脚本对图片素材进行翻转、随机颜色等基本变换来对数据集规模进行扩充。此为额外操作,不影响yolo-darknet训练过程。
数据集的标注采用的是基于python的ImageLabel,标注界面是可视化的,流程基本上是:
- 设置你标注的物体对应的标签,例如dog,cat等,可以设置默认标签
- 打开素材文件夹到程序中,设置当前的标签,对图片进行逐个画框标注
- 标注后自动生成数个xml文件,xml文件的内容一般如下
1 | <annotation> |
基本上就是对于标注的方框的位置和大小的记录。标注生成的是整个VOC数据集文件夹,一般有两个文件夹:图片文件夹Image和标记文件夹xml。标记文件夹中每一个xml文件的文件名基本上都对应了的图片文件夹中的图片文件。
应当注意的是,一旦移动了xml文件夹或整个数据集文件夹,必须将所有xml文件中的图片文件夹、图片路径改成对应的新文件夹、新路径,否则必然报错。
但问题是,一旦数据集规模像本项目一样巨大时,人工逐个更改xml就十分困难。所以需要python脚本进行批量文件处理。此处摘录一部分代码
1 | # coding=utf-8 |
注:以上代码是本人为了修正数据集格式自行编写的,具有很强的临时性,是不同功能的python代码之间的整合,如果不需要某些功能,可以将对应代码手动注释掉
训练数据集和验证数据集的拆分
数据集应当分成训练集和验证集,以便于对训练效果进行评估。
这里作者直接参考了这篇CSDN上的文章《YOLO训练自己的数据集》中的python脚本,内容摘录如下:
下载链接:http://pan.baidu.com/s/1hs22I7U 密码:wdv0
运行traindata.py:生成trainImage文件夹,存放训练图片;生成trainImageXML文件夹,存放训练图片xml标签;生成validateImage文件夹,存放验证集图片;生成validateImageXML文件夹,存放验证集图片的xml标签。
运行trans.py,生成trainImageLabelTxt文件夹,存放训练图片通过xml标签转化得到的txt文件(若在训练过程提示txt文件找不到,则把此文件夹下的txt文件夹移动到trainImage文件夹);生成validateImageLabelTxt文件夹,道理一样。
另外得到的trainImagePath.txt和validateImagePath.txt存放着训练图片和验证图片的路径。
下载好的python脚本一般不能立即用,根据运行python脚本出现的报错,应当对其进行相应的修改,例如:
1 | classes = ["cat"] #把这个标签改成你自己的数据集中标记的标签 |
对darknet的配置和更改
darknet本身并非完全开箱即用的图像识别训练框架,因此需要对它进行有针对性的配置和必要的更改。此处同样是根据《YOLO训练自己的数据集》以及其他几篇文章的指导和建议进行配置的,主要有以下几点:
首先,对darknet的cfg/voc.data进行配置
1 | classes= 标签类别总数 |
在data文件夹下的names文件中,每行写一条标签名称
其次,对要使用的神经网络版本yolo2-voc对应的配置文件yolo2-voc.cfg,应当更改以下几处:
- 将最后的[region]层神经网络的配置中的classes改为1(即标记类别的总数)
- 将最后一个[convolutional]卷积层中的filter改为30(filter的公式filters=(classes+ coords+ 1) (NUM) ,我的是(1+4+1) 5=30)
注:这里coords可以认为是坐标,设置的标记是一个方框则取4。NUM是神经网络的层数。filter公式的来源请参见国外开发者们的讨论:https://groups.google.com/forum/#!topic/darknet/B4rSpOo84yg
训练
在yolo的官网下载预训练模型,地址:http://pjreddie.com/media/files/darknet53.conv.74
并执行训练命令:
1 | ./darknet detector train cfg/voc.data cfg/yolov2-voc.cfg darknet53.conv.74 |
之后便开始了对神经网络的训练,在1000次训练之内,每100次就在backup文件夹中生成一次权重模型,在1000次训练以上,每10000次生成一次权重模型。本项目的最终训练次数达到了50000次。
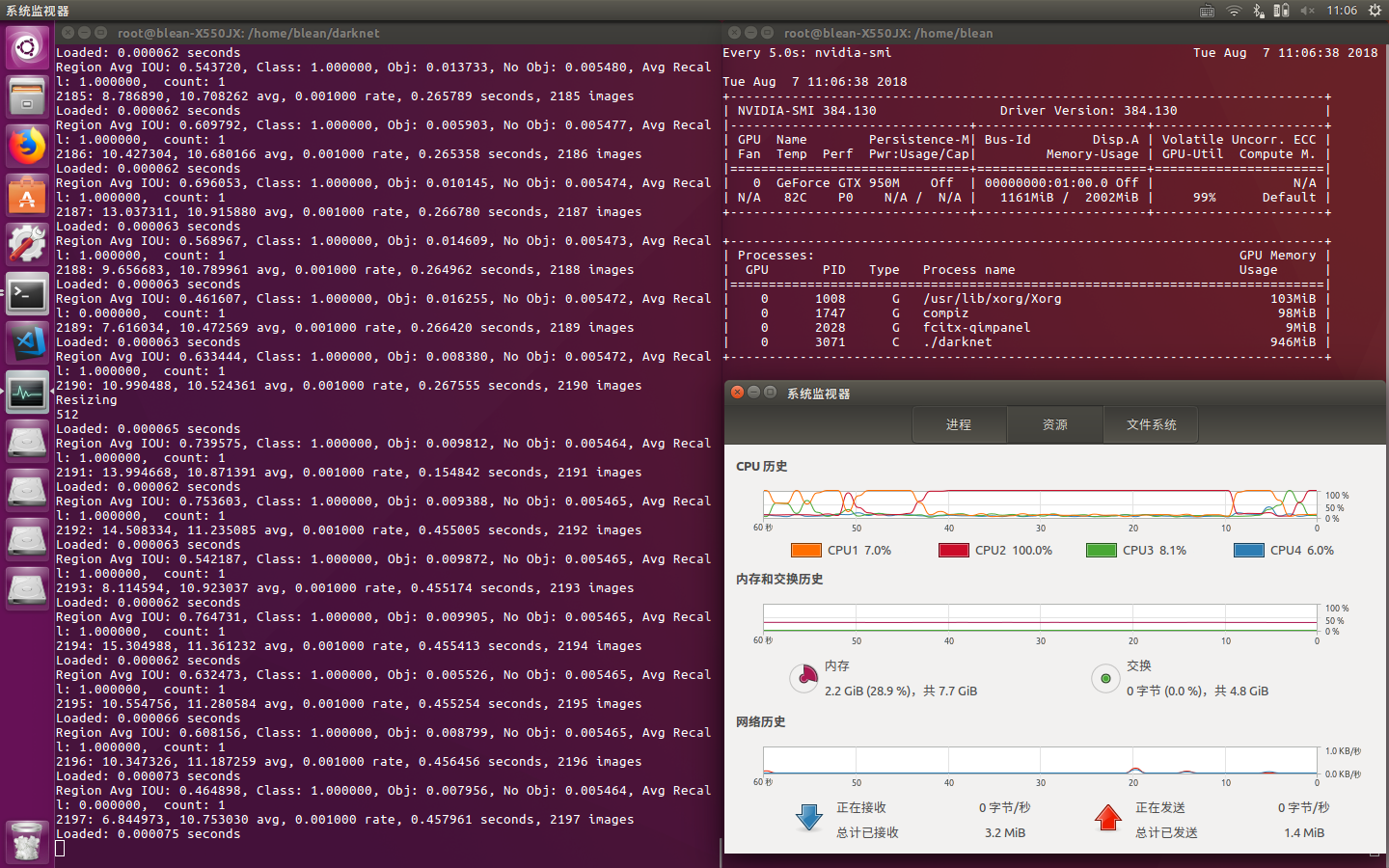
上图为训练到500次左右时的结果截图
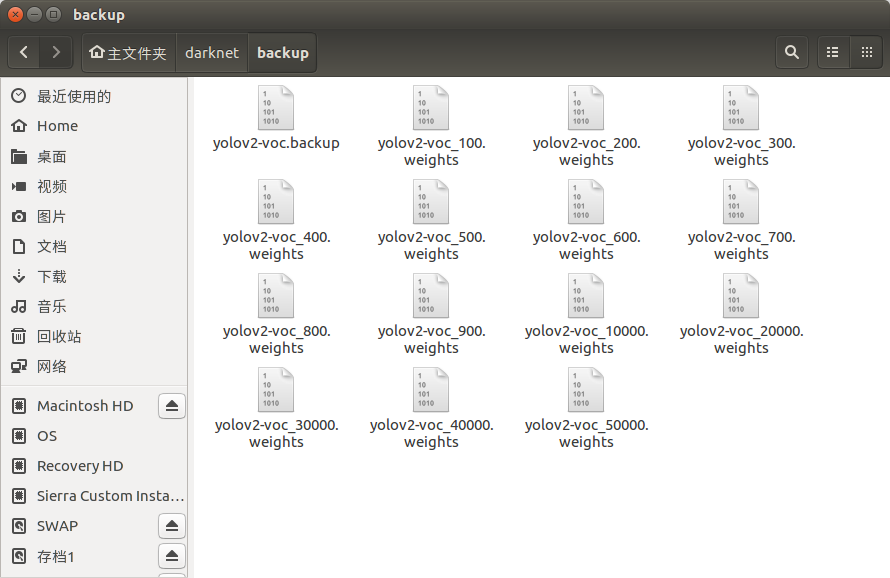
训练生成的模型文件
批量测试、评估以及需要对darknet进行的相应修改
本人之前的笔记中曾经提到了使用单张图片测试,以及连接计算机摄像头、网络视频推流进行实时识别的命令,命令内容大致如下:
单张图片:1
./darknet detect cfg/yolo.cfg yolo.weight data/horses.jpg
电脑摄像头:1
./darknet detector demo cfg/voc.data cfg/tiny-yolo-voc.cfg weights/tiny-yolo-voc.weights
手机摄像头(通过网络视频实时推流,使用工具为IP摄像头APP):
1 | ./darknet detector demo data/coco.data yolo.cfg yolo.weights http://192.168.191.2:8080/video |
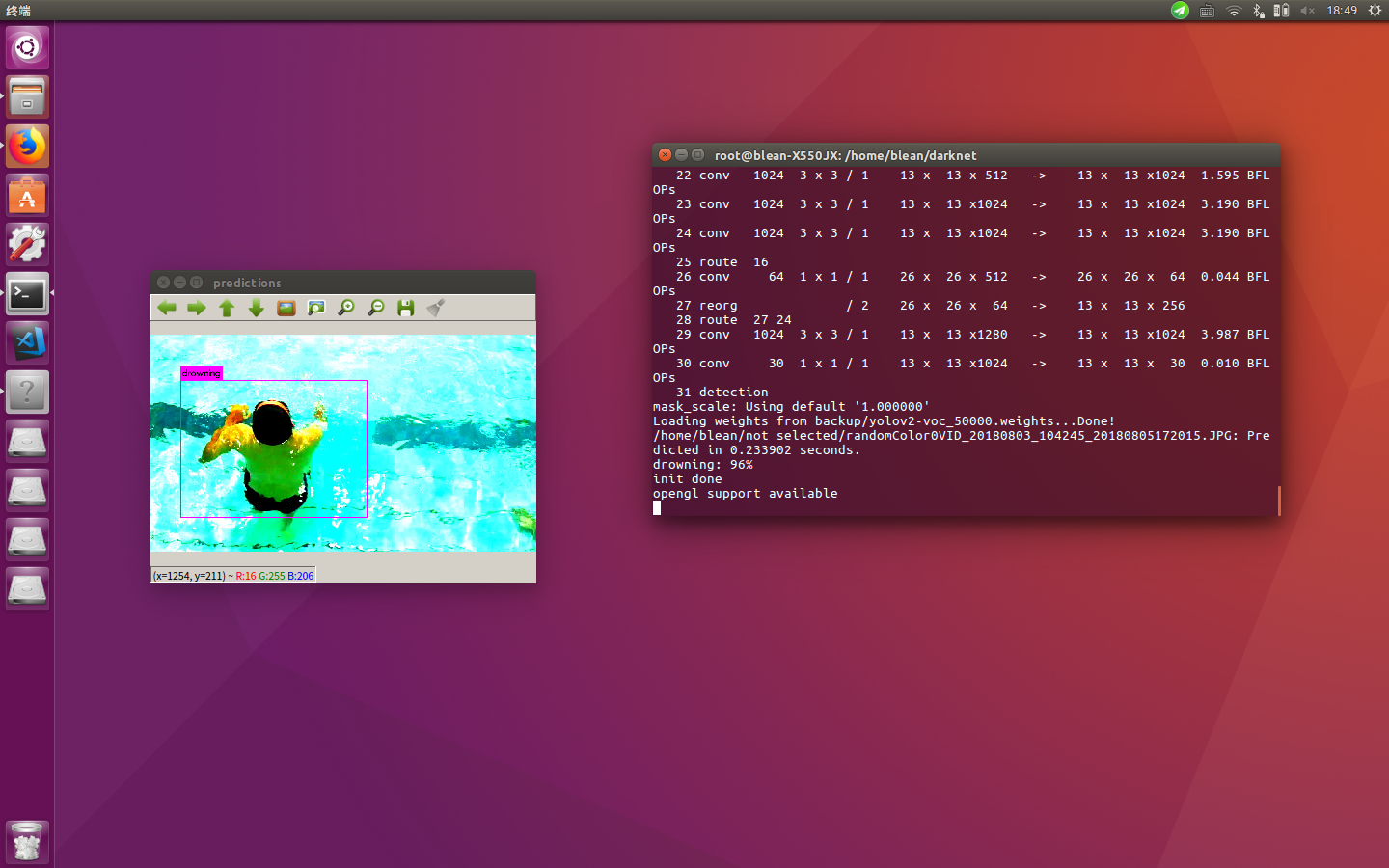
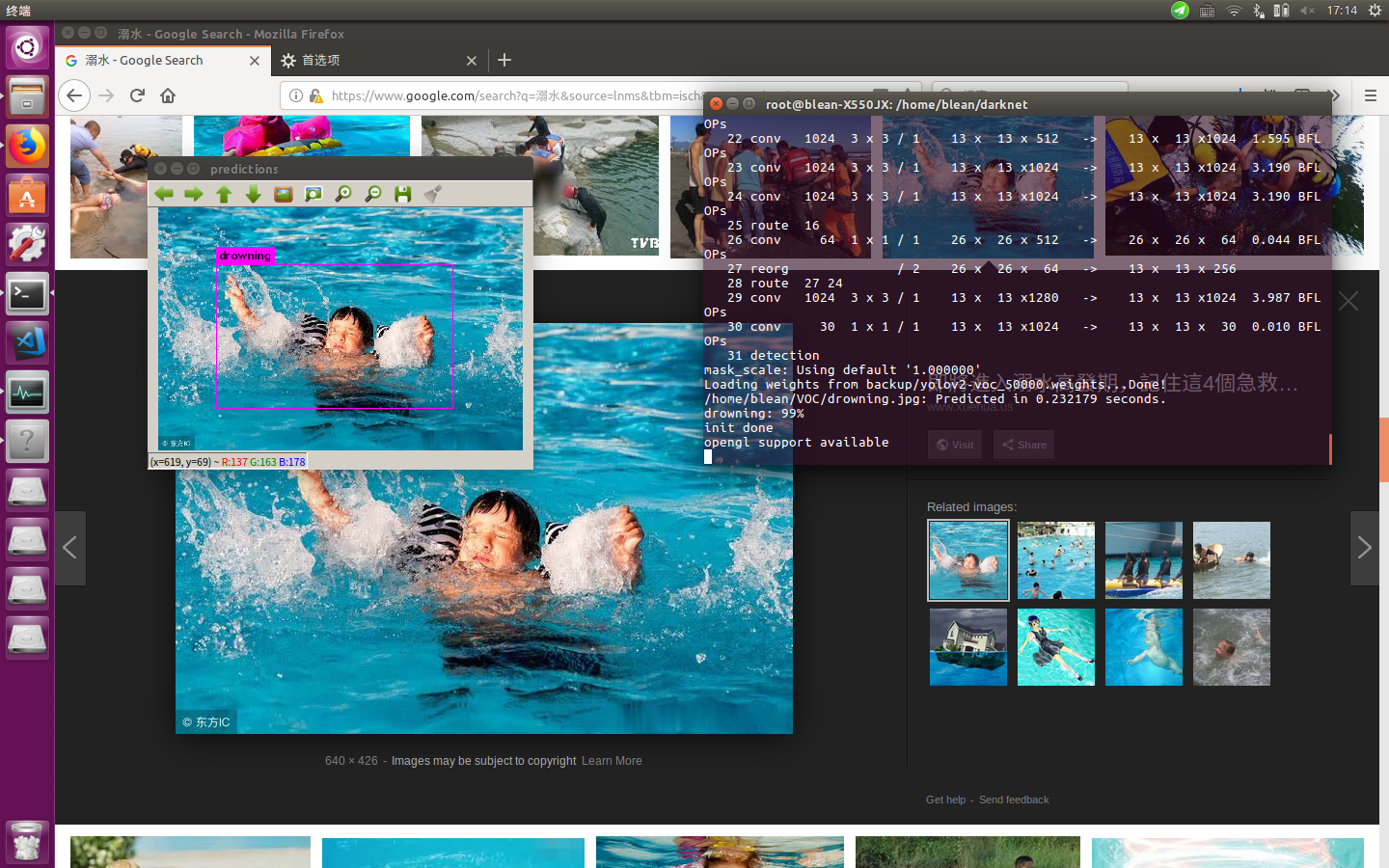
得到的效果大致如下:
实地场景:
网络图片:
但是,可以看出这样手动输入命令进行逐个测试的方法,在测试上文中提到的从标记数据集中拆分出来的有一定数量图片的验证集时十分地不友好。而且必须手工收集每次测试中得到的准确度信息、手工进行统计计算。
所以这里参考了CSDN上的另一篇文章《YOLOv3批量测试图片并保存在自定义文件夹下》以及简书上的一篇文章《Darknet 评估训练好的网络的性能》对darknet中的example文件夹下的detector.c文件中的代码进行更改,以便于进行批量测试、统计、评估模型在验证集上的准确度,并输出结果:
- 修改validate_detector_recall函数定义和调用为:
1 | void validate_detector_recall(char *datacfg, char *cfgfile, char *weightfile) |
- 修改validate_detector_recall的初始化代码
修改前:1
2list *plist = get_paths("data/voc.2007.test");
char **paths = (char **)list_to_array(plist);
修改后:1
2
3
4list *options = read_data_cfg(datacfg);
char *valid_images = option_find_str(options, "valid", "/home/blean/VOC/validateImagePath.txt");
list *plist = get_paths(valid_images);
char **paths = (char **)list_to_array(plist);
- 修改结束后需要重新编译darknet主程序,命令如下
1 | make -j8 |
在完成上述修改后即可使用darknet的recall命令进行评估测试并输出结果
1 | ./darknet detector recall cfg/voc.data cfg/yolov2-voc.cfg backup/yolov2-voc_50000.weights -out drowning_recall.txt |
输出的结果如下:
1 | Number Correct Total Rps/Img IOU Recall |
其中各项参数的解释如下:
- Number表示处理到第几张图片。
- Correct表示正确的识别出了多少bbox(即标记目标物体的方框)。这个值算出来的步骤是这样的,丢进网络一张图片,网络会预测出很多bbox,每个bbox都有其置信概率,概率大于threshold的bbox与实际的bbox,也就是labels中txt的内容计算IOU,找出IOU最大的bbox,如果这个最大值大于预设的IOU的threshold,那么correct加1。
- Total表示实际有多少个bbox。
- Rps/img表示平均每个图片会预测出来多少个bbox。
- IOU: 这个是预测出的bbox和实际标注的bbox的交集 除以 他们的并集。显然,这个数值越大,说明预测的结果越好。
- Recall召回率, 意思是检测出物体的个数 除以 标注的所有物体个数。通过代码我们也能看出来就是Correct除以Total的值。
可以从最后一条代表处理了全部验证集的统计结果看出,经过验证集的检验,训练得出的模型识别目标物体的总正确率大致在86%左右,可以说训练效果较为理想。
参考资料
- YOLO-darknet官网
https://pjreddie.com/darknet/yolo/ - YOLO训练自己的数据集:
https://blog.csdn.net/qq_34484472/article/details/73135354 - YOLOv3批量测试图片并保存在自定义文件夹下:
https://blog.csdn.net/mieleizhi0522/article/details/79989754 - Darknet 评估训练好的网络的性能:
https://blog.csdn.net/mieleizhi0522/article/details/79989754 - Environment-Configuration-for-Yolo-darknet | NeXT (就是之前的那篇笔记)
https://lmy98129.github.io/2018/02/20/Environment-Configuration-for-Yolo-darknet
最后,这是本站的第八篇正式发文,感谢阅读。
如有意见和建议,欢迎通过首页的联系方式联系作者,
本文参考资料均来源于网络,作者保留相关权利,转载请注明出处。