
PRIR Lab, University of Science and Technology Beijing
Object Detection, AI4Science
News
- 2025/02/15: Our paper "HA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection" is accepted by TMM'25!
- 2025/01/23: Our paper "OSS-OCL: Occlusion Scenario Simulation and Occluded-edge Concentrated Learning for Pedestrian Detection" is accepted by PR Letters'25!
- 2024/07/16: Our paper "Unsupervised Multi-view Pedestrian Detection" is accepted by ACM MM'24!
- 2023/08/21: Our paper "Feature Implicit Enhancement via Super-Resolution for Small Object Detection" is accepted by PRCV'23!
- 2023/06/08: Our paper "Towards Discriminative Semantic Relationship for Fine-grained Crowd Counting" is scheduled in ICME'23 oral session! (Please refer to "Tuesday 11th July"→"10:30 - 12:00"→"O2 - Semantic Processing I" on the official website.)
- 2023/03/13: Our paper "Towards Discriminative Semantic Relationship for Fine-grained Crowd Counting" is accepted by ICME'23!
- 2023/02/28: Our paper "VLPD: Context-Aware Pedestrian Detection via Vision-Language Semantic Self-Supervision" is accepted by CVPR'23!
- 2022/06/30: Our paper "CAliC: Accurate and Efficient Image-Text Retrieval via Contrastive Alignment and Visual Contexts Modeling" is accepted by ACM MM'22!
- 2020/12/02: Our paper "Adaptive Pattern-Parameter Matching for Robust Pedestrian Detection" is accepted by AAAI'21!
Publications
HA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection (TMM'25)
Yuqi Ma#, Mengyin Liu#, Chao Zhu*, Xu-Cheng Yin. University of Science and Technology Beijing. (# Equal contribution)
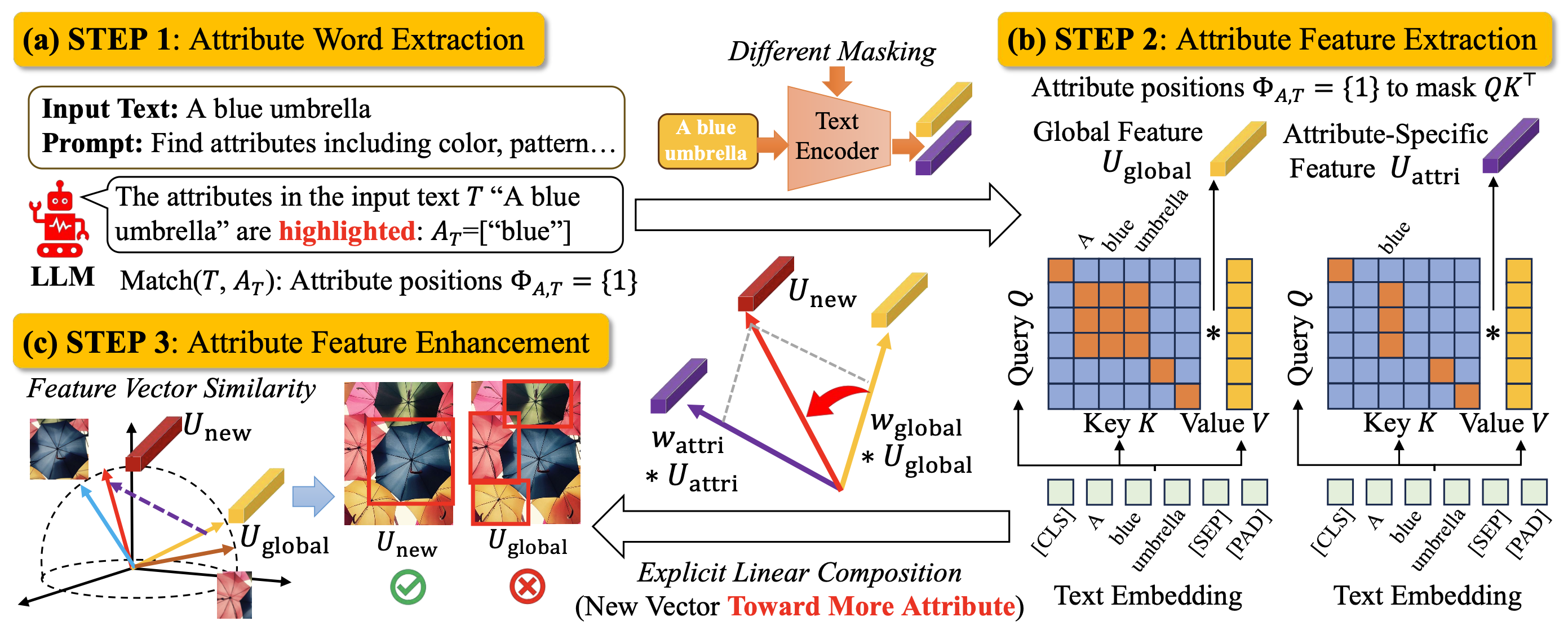
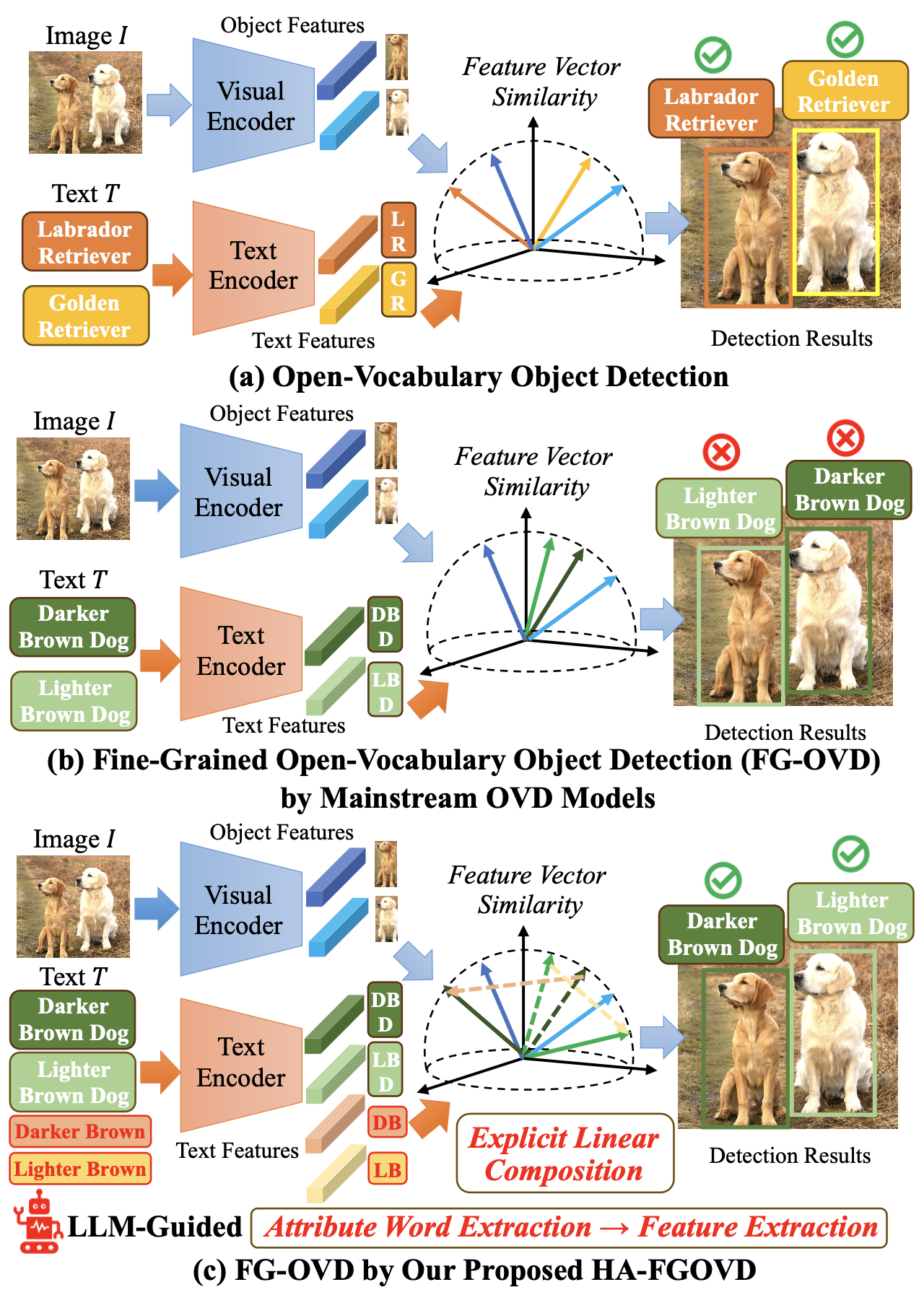
Open-vocabulary object detection (OVD) models are considered to be Large Multi-modal Models (LMM), due to their extensive training data and a large number of parameters. Main- stream OVD models prioritize object coarse-grained category rather than focus on their fine-grained attributes, e.g., colors or materials, thus failed to identify objects specified with certain attributes. Despite being pretrained on large-scale image-text pairs with rich attribute information, their latent feature space does not highlight these fine-grained attributes. In this paper, we introduce HA-FGOVD, a universal and explicit method that enhances the attribute-level detection capabilities of frozen OVD models by highlighting fine-grained attributes in explicit linear space. Our approach uses a LLM to extract attribute words in input text as a zero-shot task. Then, token attention masks are adjusted to guide text encoders in extracting both global and attribute-specific features, which are explicitly composited as two vectors in linear space to form a new attribute-highlighted feature for detection tasks. The composition weight scalars can be learned or transferred across different OVD models, showcasing the universality of our method. Experimental results show that HA-FGOVD achieves state-of-the-art performance on the FG- OVD benchmark and demonstrates promising generalization on the OVDEval benchmark, suggesting that our method addresses significant limitations in fine-grained attribute detection and has potential for broader fine-grained detection applications.
Resources: [Paper]
OSS-OCL: Occlusion Scenario Simulation and Occluded-edge Concentrated Learning for Pedestrian Detection (PR Letters'25)
Keqi Lu1,2, Chao Zhu2*, Mengyin Liu2, Xu-Cheng Yin2.
1Children's Hospital, Zhejiang University School of Medicine. 2University of Science and Technology Beijing.
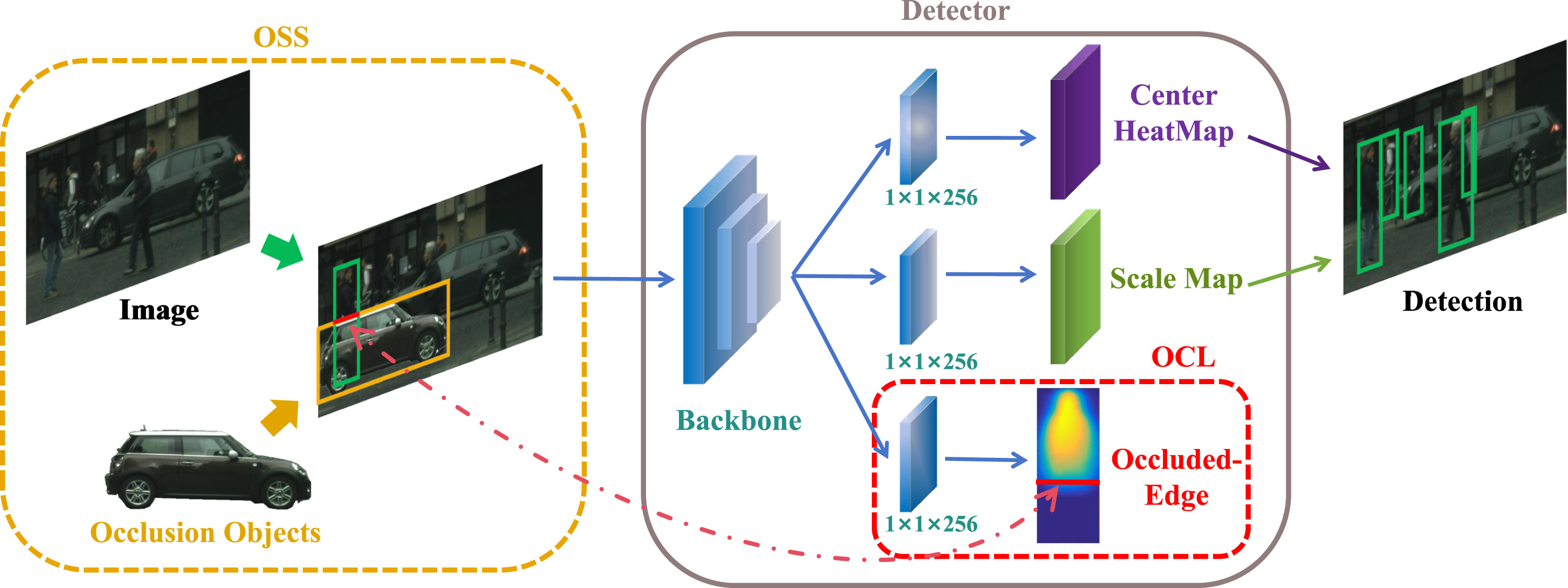
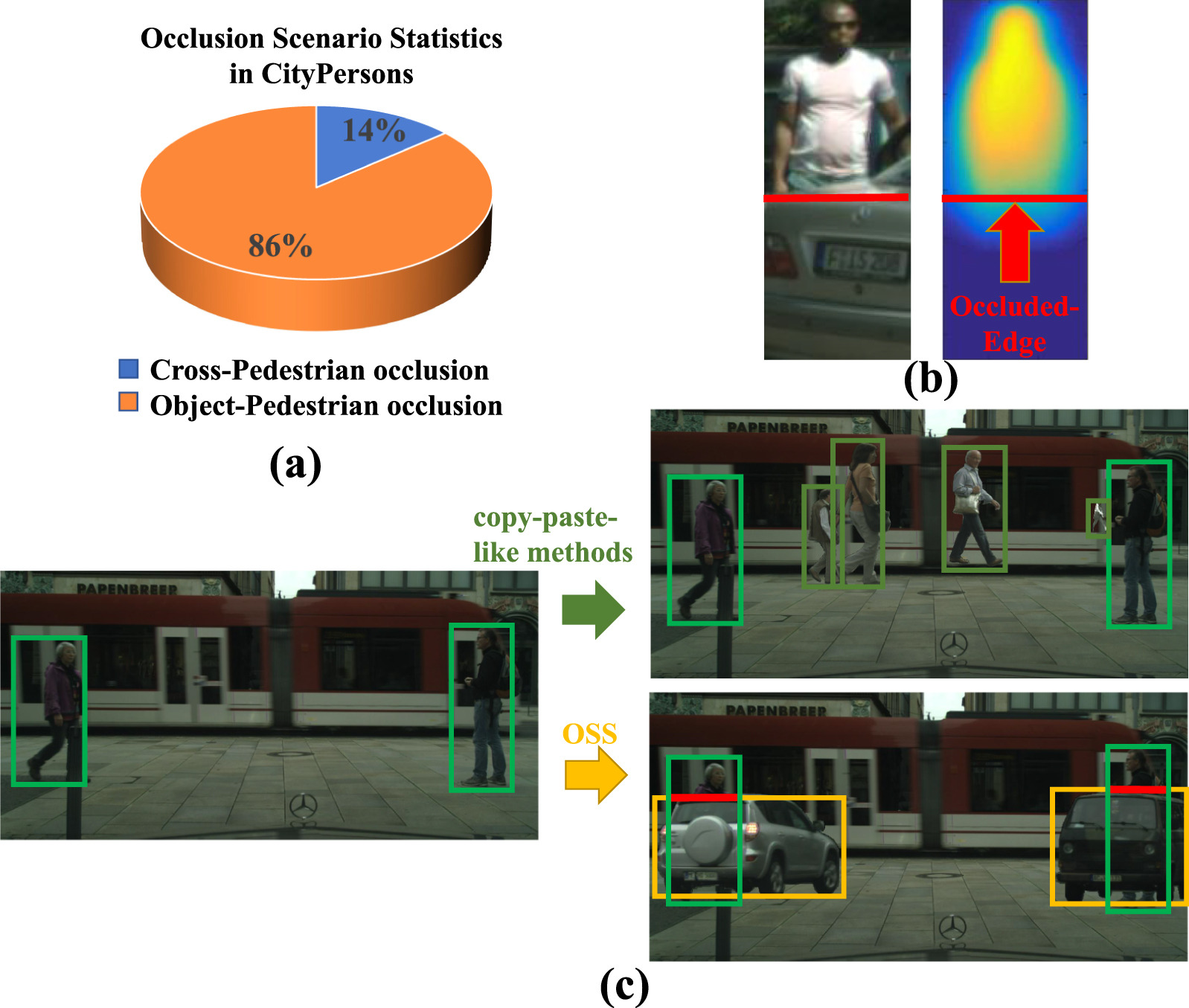
Abstract Pedestrian detection plays an important role in realistic applications. However, heavily occluded pedestrians, with their incomplete and unusual appearances, are easily missed during detection. To address this issue, previous works use copy-paste method or generate dummies to assist the detectors in learning better detection capability. Nevertheless, these works focus on less frequent occlusion in natural scenes and lead to less performance gain. Therefore, we firstly propose a novel method named Occlusion Scenario Simulation (OSS), which simulates the most classical occlusion scenario by inserting objects adjacent to the non- or partial-occluded pedestrians. Secondly, in order to supervise the detector to better learn the occlusion information, we also propose a new method namely Occluded-edge Concentrated Learning (OCL) to predict the offset of occluded-edge between pedestrians and occlusions. Extensive experiments on popular pedestrian datasets demonstrate that our proposed OSS-OCL outperforms some state-of-the-art methods, particularly in the cases of heavy occlusion.
Resources: [Paper]
Unsupervised Multi-view Pedestrian Detection (ACM MM'24)
Mengyin Liu, Chao Zhu*, Shiqi Ren, Xu-Cheng Yin. University of Science and Technology Beijing.
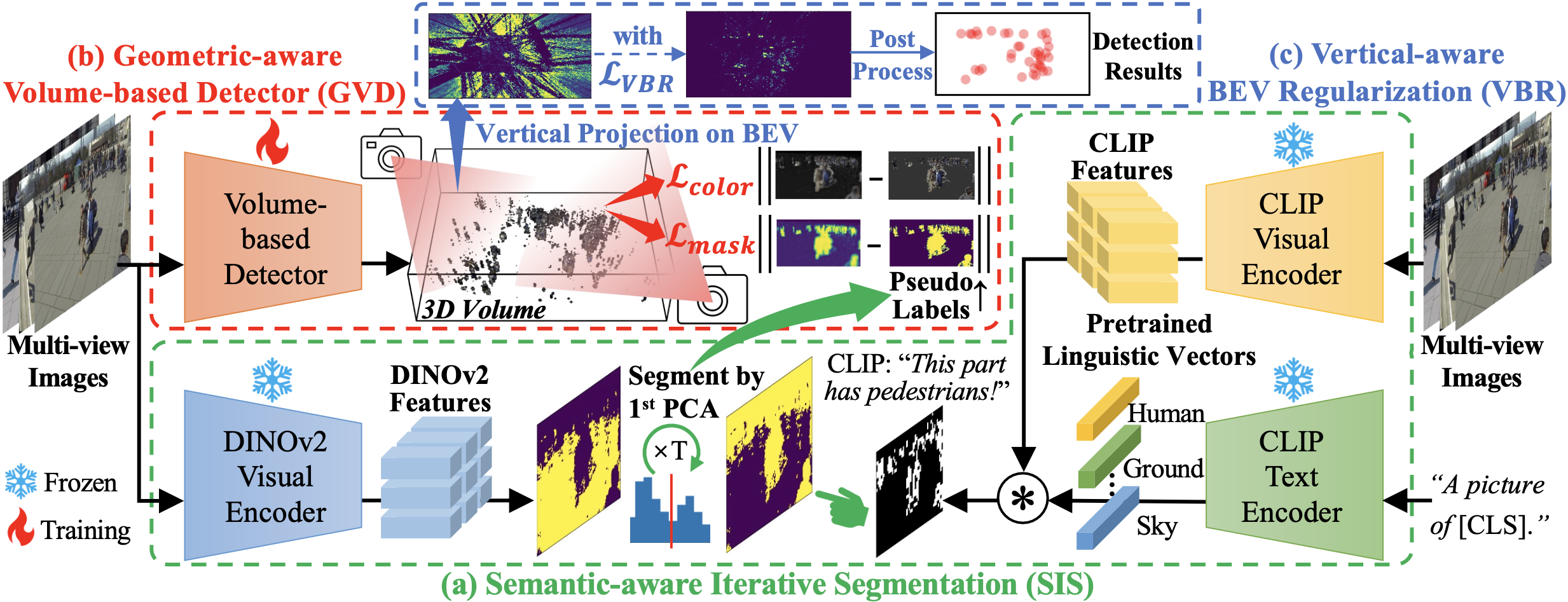
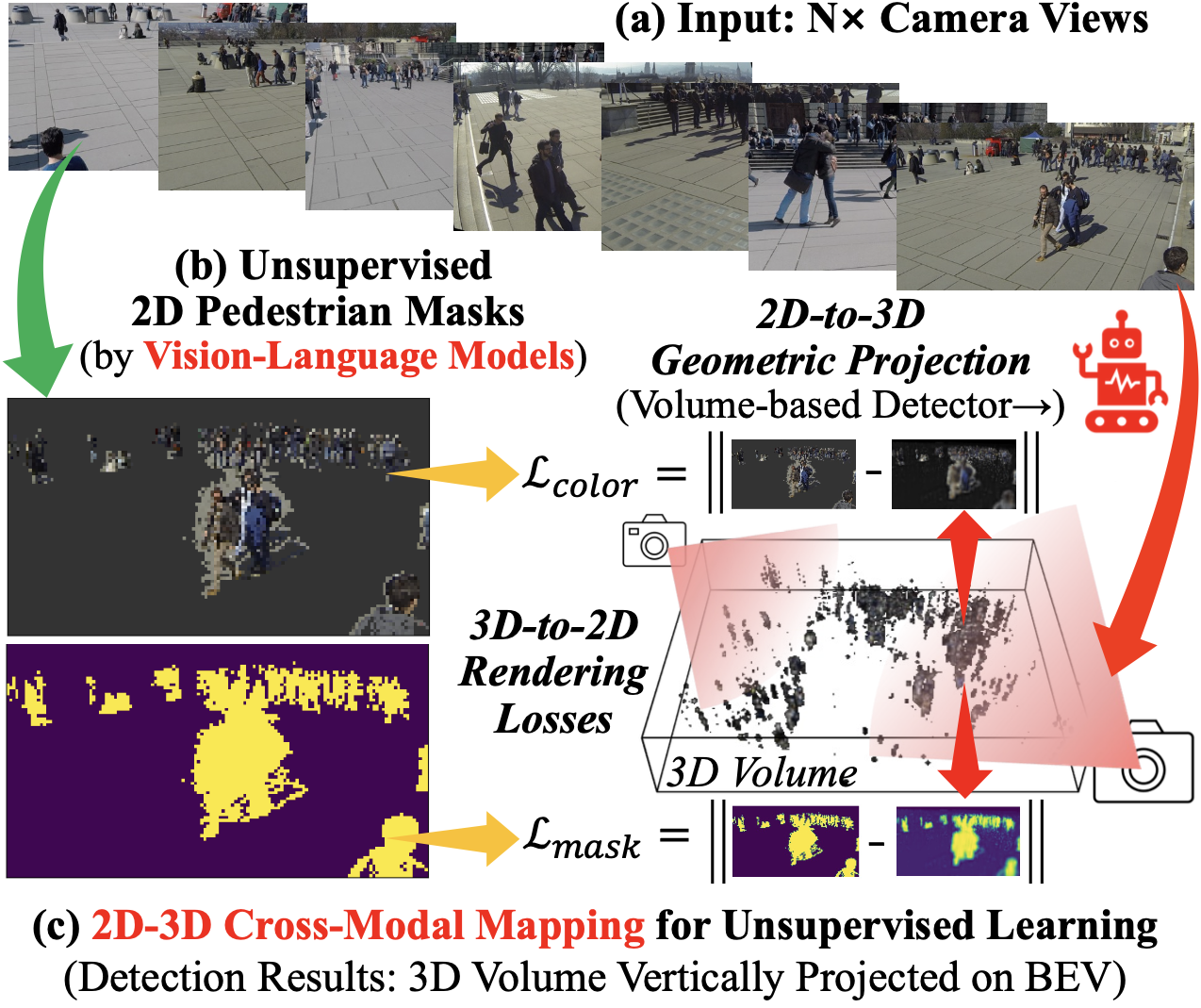
Abstract With the prosperity of the intelligent surveillance, multiple cameras have been applied to localize pedestrians more accurately. However, previous methods rely on laborious annotations of pedestrians in every frame and camera view. Therefore, we propose in this paper an Unsupervised Multi-view Pedestrian Detection approach (UMPD) to learn an annotation-free detector via vision-language models and 2D-3D cross-modal mapping: 1) Firstly, Semantic-aware Iterative Segmentation (SIS) is proposed to extract unsupervised representations of multi-view images, which are converted into 2D masks as pseudo labels, via our proposed iterative PCA and zero-shot semantic classes from vision-language models; 2) Secondly, we propose Geometry-aware Volume-based Detector (GVD) to end-to-end encode multi-view 2D images into a 3D volume to predict voxel-wise density and color via 2D-to-3D geometric projection, trained by 3D-to-2D rendering losses with SIS pseudo labels; 3) Thirdly, for better detection results, i.e., the 3D density projected on Birds-Eye-View, we propose Vertical-aware BEV Regularization (VBR) to constrain pedestrians to be vertical like the natural poses. Extensive experiments on popular multi-view pedestrian detection benchmarks Wildtrack, Terrace, and MultiviewX, show that our proposed UMPD, as the first fully-unsupervised method to our best knowledge, performs competitively to the previous state-of-the-art supervised methods.
Resources: [Paper], [Supplementary Materials], [Code]
Feature Implicit Enhancement via Super-Resolution for Small Object Detection (PRCV'23)
Zhehao Xu, Mengyin Liu, Chao Zhu*, Fang Zhou, Xu-Cheng Yin. University of Science and Technology Beijing.
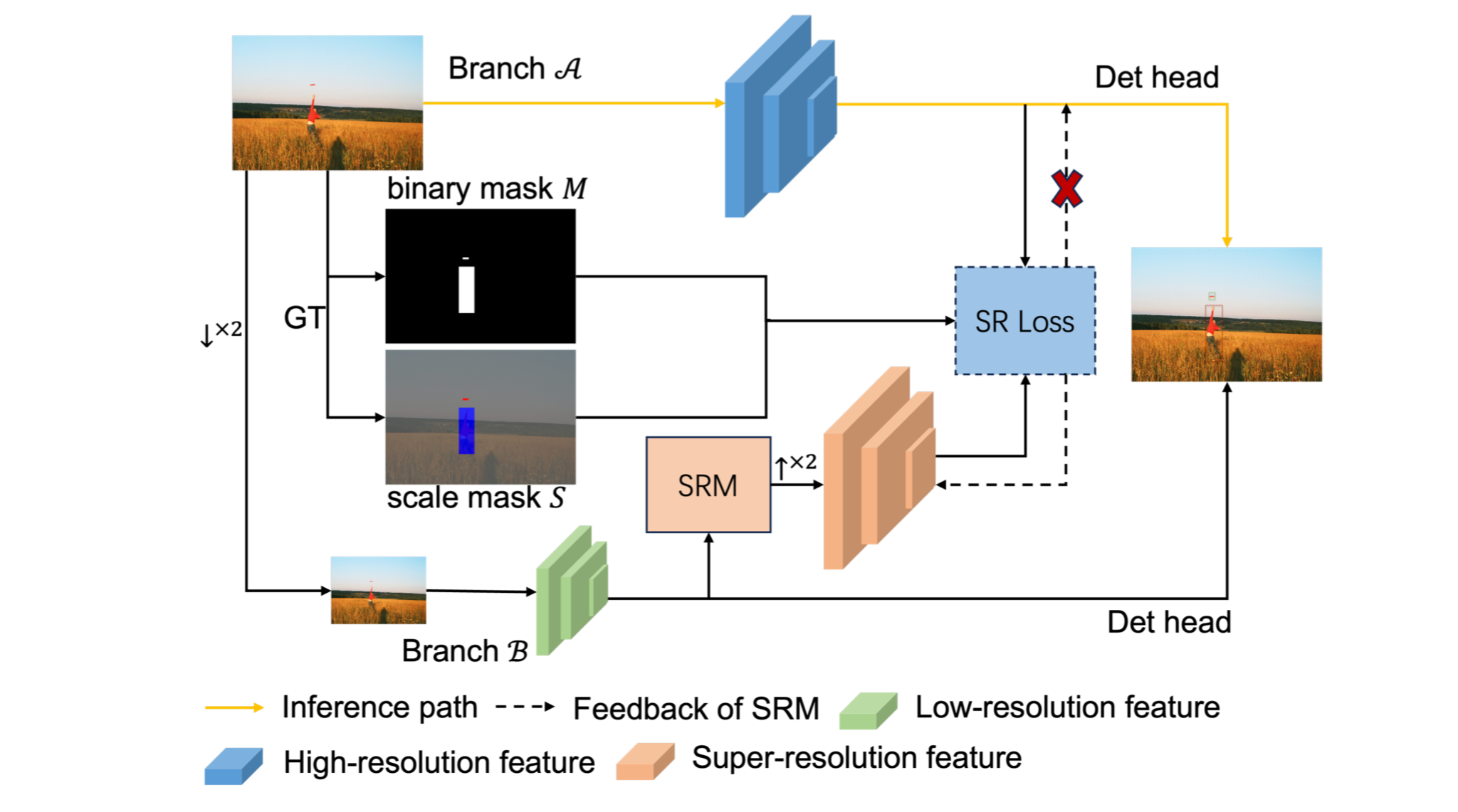

Abstract In recent years, object detection has made significant strides due to advancements in deep convolutional neural networks. However, the detection performance for small objects remains challenging. The visual information of small objects is easily confused with the background and even gets lost in a series of downsampling operations due to the limited number of pixels, resulting in poor representations. In this paper, we propose a novel approach namely Feature Implicit Enhancement via Super-Resolution (FIESR) to learn more robust feature representations for small object detection. Our FIESR consists of two detection branches and requires two steps of training. Firstly, the detector learns the relationship between low-resolution and corresponding original high-resolution images to enhance the representations of small objects by minimizing a super-resolution loss between the two branches. Secondly, the detector is fine-tuned on original resolution images to fit extremely large objects. Additionally, our FIESR could be applied to various popular detectors such as Faster-RCNN, RetinaNet, FCOS, and DyHead. Our FIESR achieves competitive results on COCO dataset and is proved effective and flexible by extensive experiments.
Resources: [Paper]
Towards Discriminative Semantic Relationship for Fine-grained Crowd Counting (ICME'23 oral)
Shiqi Ren, Chao Zhu*, Mengyin Liu, Xu-Cheng Yin. University of Science and Technology Beijing.
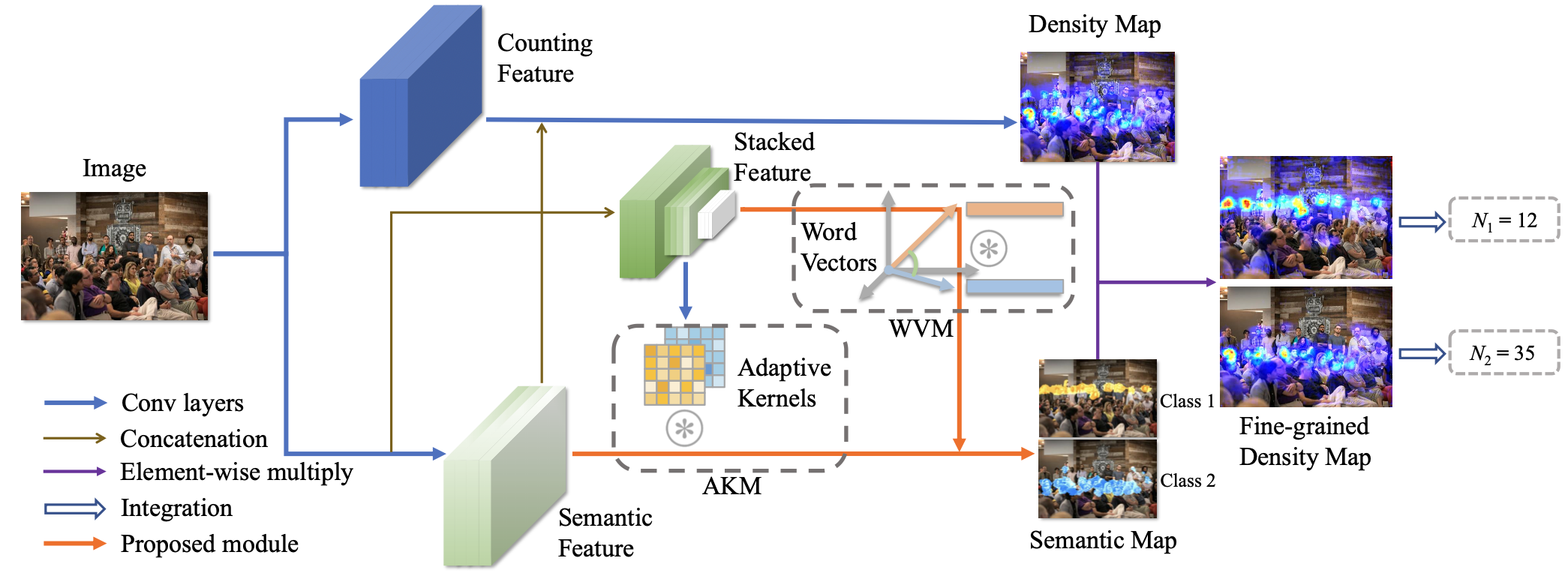
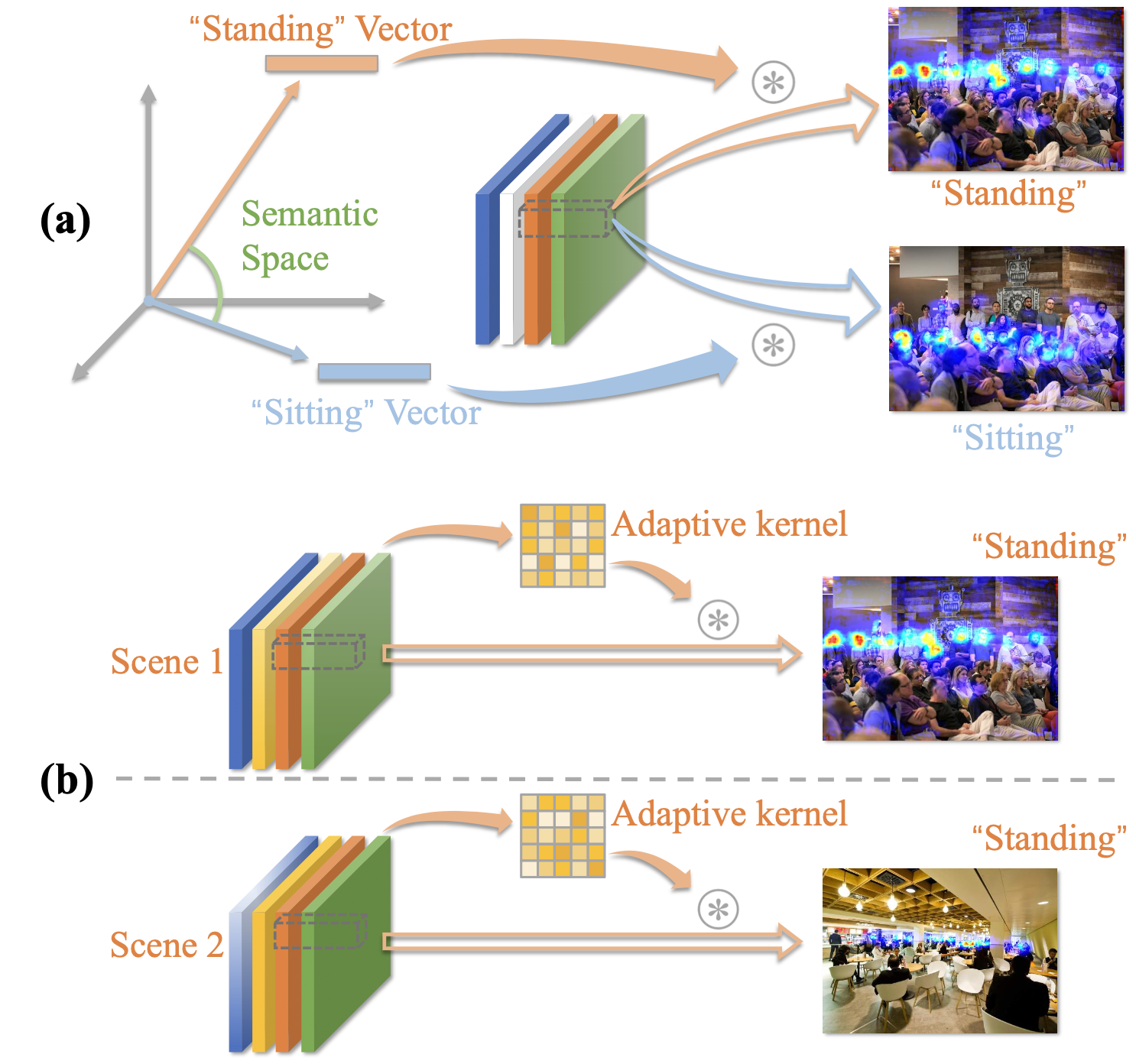
Abstract As an extended task of crowd counting, fine-grained crowd counting aims to estimate the number of people in each semantic category instead of the whole in an image, and faces challenges including 1) inter-category crowd appearance similarity, 2) intra-category crowd appearance variations, and 3) frequent scene changes. In this paper, we propose a new fine-grained crowd counting approach named DSR to tackle these challenges by modeling Discriminative Semantic Relationship, which consists of two key components: Word Vector Module (WVM) and Adaptive Kernel Module (AKM). The WVM introduces more explicit semantic relationship information to better distinguish people of different semantic groups with similar appearance. The AKM dynamically adjusts kernel weights according to the features from different crowd appearance and scenes. The proposed DSR achieves superior results over state-of-the-art on the standard dataset. Our approach can serve as a new solid baseline and facilitate future research for the task of fine-grained crowd counting.
Resources: [Paper], [Supplementary Materials]
VLPD: Context-Aware Pedestrian Detection via Vision-Language Semantic Self-Supervision (CVPR'23)
Mengyin Liu1#, Jie Jiang2#, Chao Zhu1*, Xu-Cheng Yin1.
1University of Science and Technology Beijing. 2Data Platform Department, Tencent. (# Equal contribution)
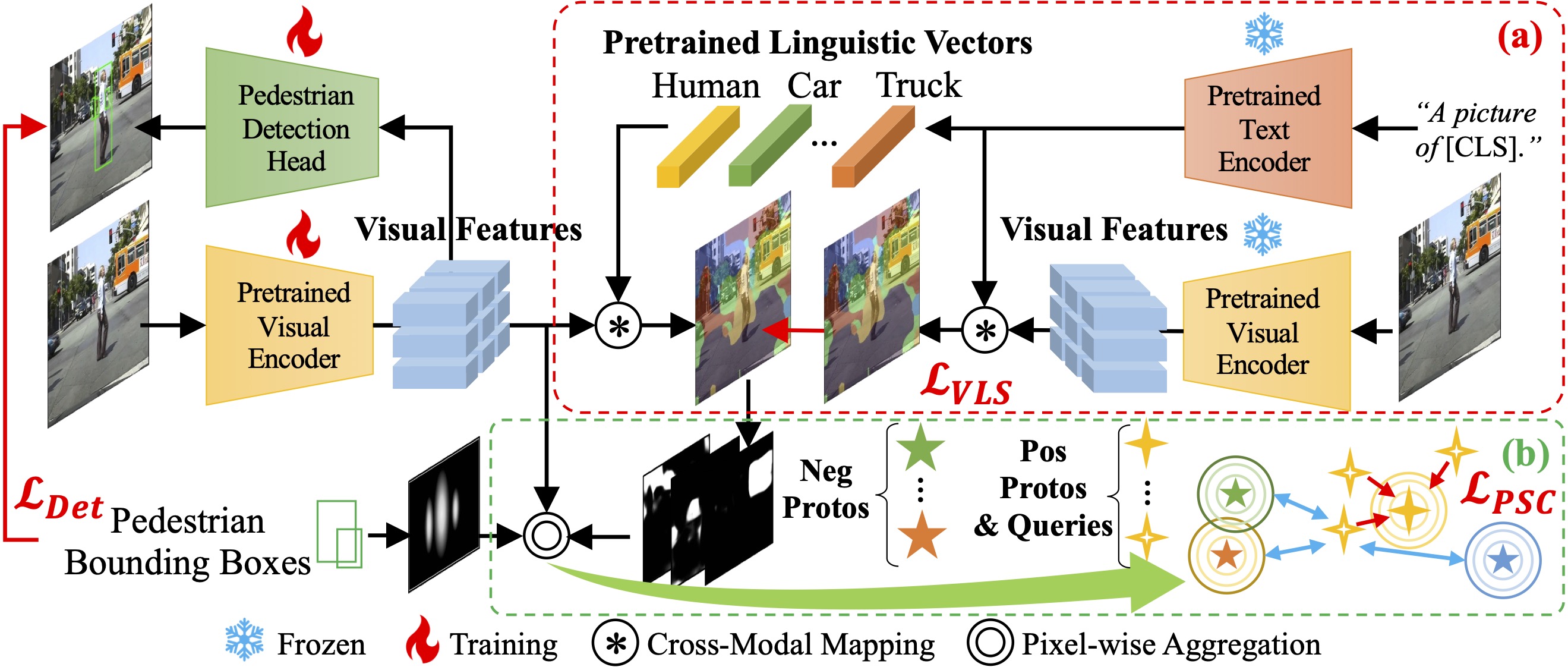
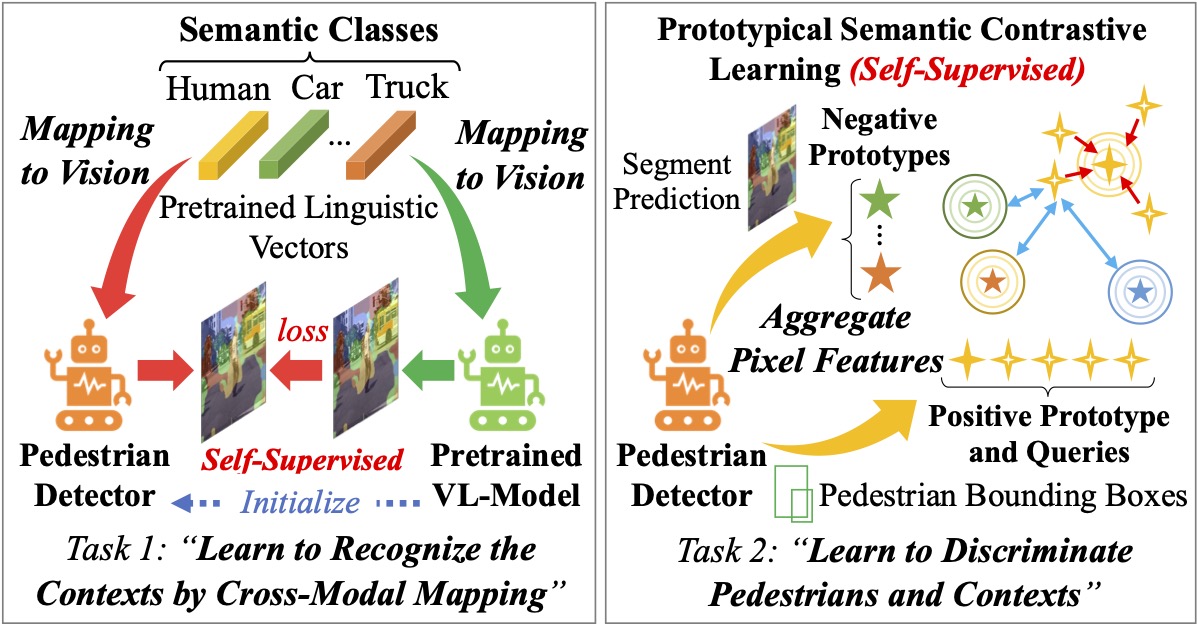
Abstract Detecting pedestrians accurately in urban scenes is significant for realistic applications like autonomous driving or video surveillance. However, confusing human-like objects often lead to wrong detections, and small scale or heavily occluded pedestrians are easily missed due to their unusual appearances. To address these challenges, only object regions are inadequate, thus how to fully utilize more explicit and semantic contexts becomes a key problem. Meanwhile, previous context-aware pedestrian detectors either only learn latent contexts with visual clues, or need laborious annotations to obtain explicit and semantic contexts. Therefore, we propose in this paper a novel approach via Vision-Language semantic self-supervision for context-aware Pedestrian Detection (VLPD) to model explicitly semantic contexts without any extra annotations. Firstly, we propose a self-supervised Vision-Language Semantic (VLS) segmentation method, which learns both fully-supervised pedestrian detection and contextual segmentation via self-generated explicit labels of semantic classes by vision-language models. Furthermore, a self-supervised Prototypical Semantic Contrastive (PSC) learning method is proposed to better discriminate pedestrians and other classes, based on more explicit and semantic contexts obtained from VLS. Extensive experiments on popular benchmarks show that our proposed VLPD achieves superior performances over the previous state-of-the-arts, particularly under challenging circumstances like small scale and heavy occlusion.
Resources: [Paper], [Supplementary Materials], [Code]
CAliC: Accurate and Efficient Image-Text Retrieval via Contrastive Alignment and Visual Contexts Modeling (ACM MM'22)
Hongyu Gao1, Chao Zhu1*, Mengyin Liu1, Weibo Gu2, Hongfa Wang2, Wei Liu2, Xu-Cheng Yin1.
1University of Science and Technology Beijing. 2Data Platform Department, Tencent.
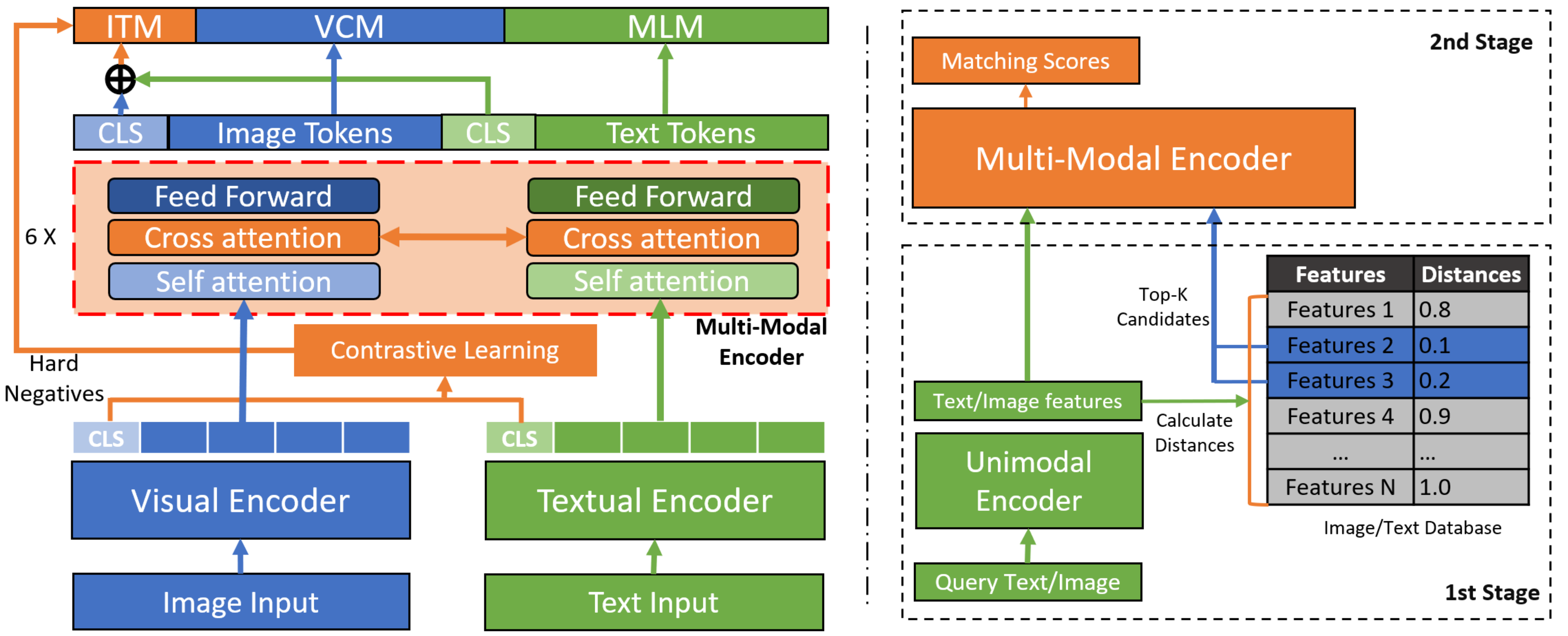
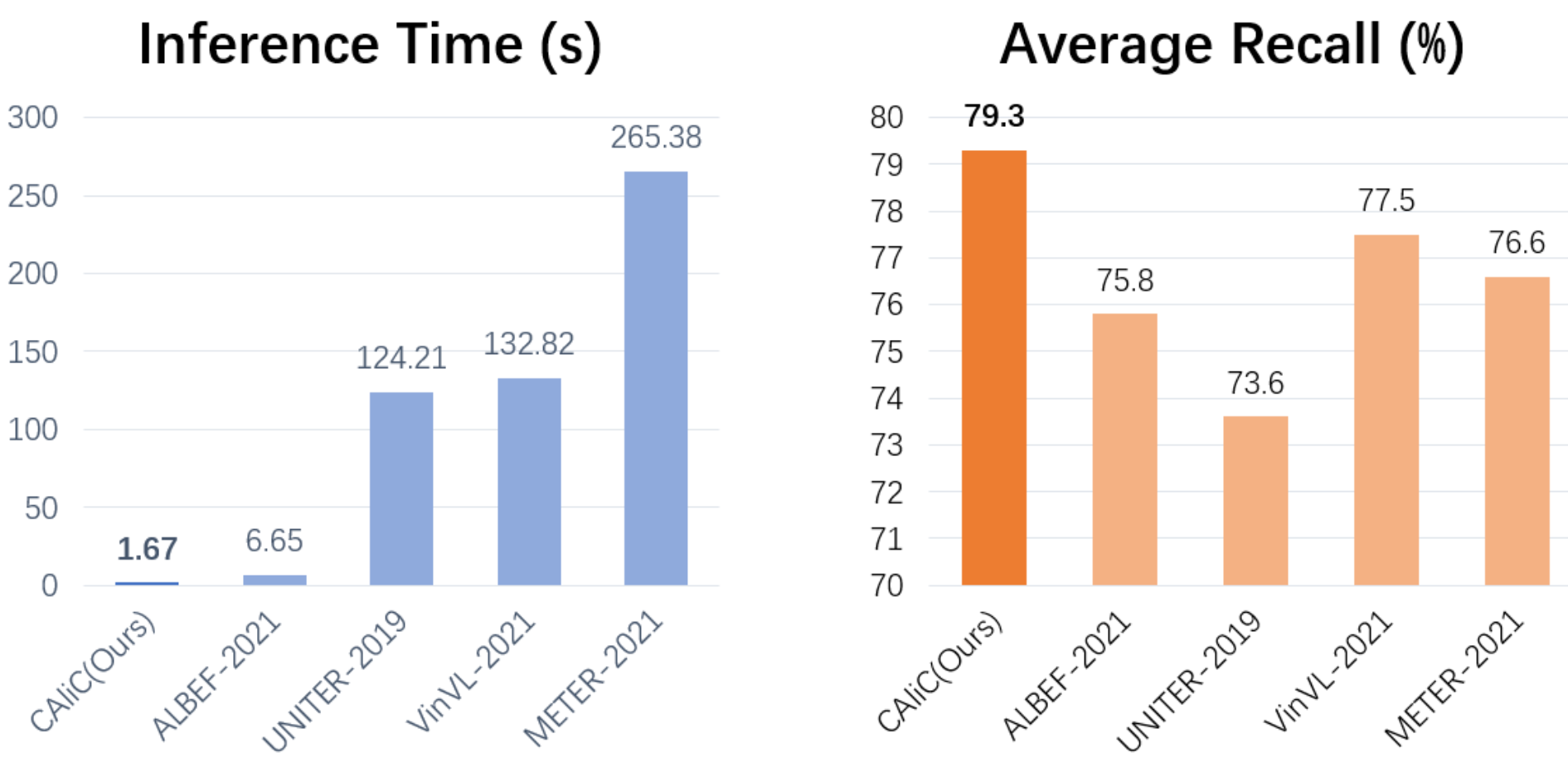
Abstract Image-text retrieval is an essential task of information retrieval, in which the models with the Vision-and-Language Pretraining (VLP) are able to achieve ideal accuracy compared with the ones without VLP. Among different VLP approaches, the single-stream models achieve the overall best retrieval accuracy, but slower inference speed. Recently, researchers have introduced the two-stage retrieval setting commonly used in the information retrieval field to the single-stream VLP model for a better accuracy/efficiency trade-off. However, the retrieval accuracy and efficiency are still unsatisfactory mainly due to the limitations of the patch-based visual unimodal encoder in these VLP models. The unimodal encoders are trained on pure visual data, so the visual features extracted by them are difficult to align with the textual features and it is also difficult for the multi-modal encoder to understand visual information. Under these circumstances, we propose an accurate and efficient two-stage image-text retrieval model via Contrastive Alignment and visual Contexts modeling (CAliC). In the first stage of the proposed model, the visual unimodal encoder is pretrained with cross-modal contrastive learning to extract easily aligned visual features, which improves the retrieval accuracy and the inference speed. In the second stage of the proposed model, we introduce a new visual contexts modeling task during pretraining to help the multi-modal encoder better understand the visual information and get more accurate predictions. Extensive experimental evaluation validates the effectiveness of our proposed approach, which achieves a higher retrieval accuracy while keeping a faster inference speed, and outperforms existing state-of-the-art retrieval methods on image-text retrieval tasks over Flickr30K and COCO benchmarks.
Resources: [Paper], [Supplementary Materials]
Adaptive Pattern-Parameter Matching for Robust Pedestrian Detection (AAAI'21)
Mengyin Liu, Chao Zhu*, Jun Wang, Xu-Cheng Yin*. University of Science and Technology Beijing.
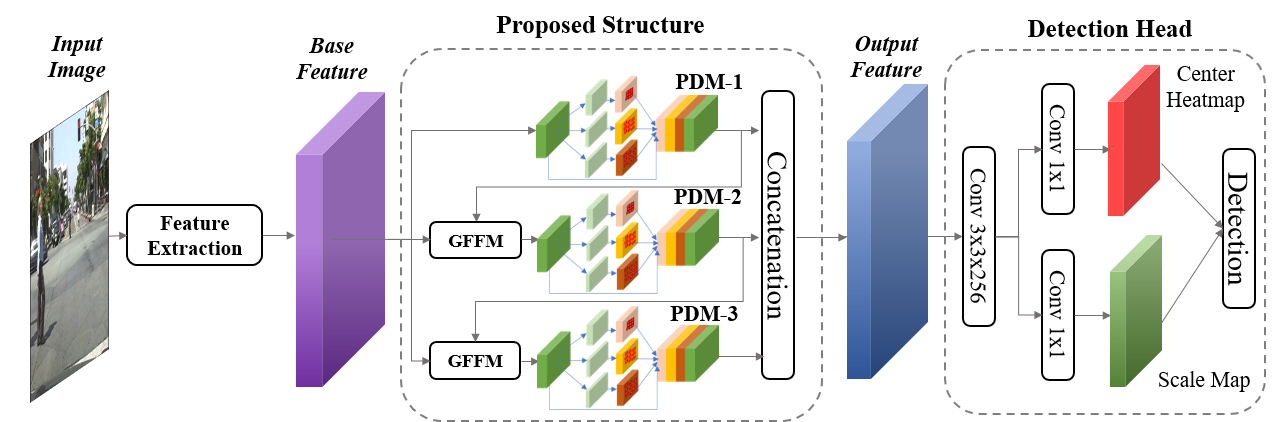
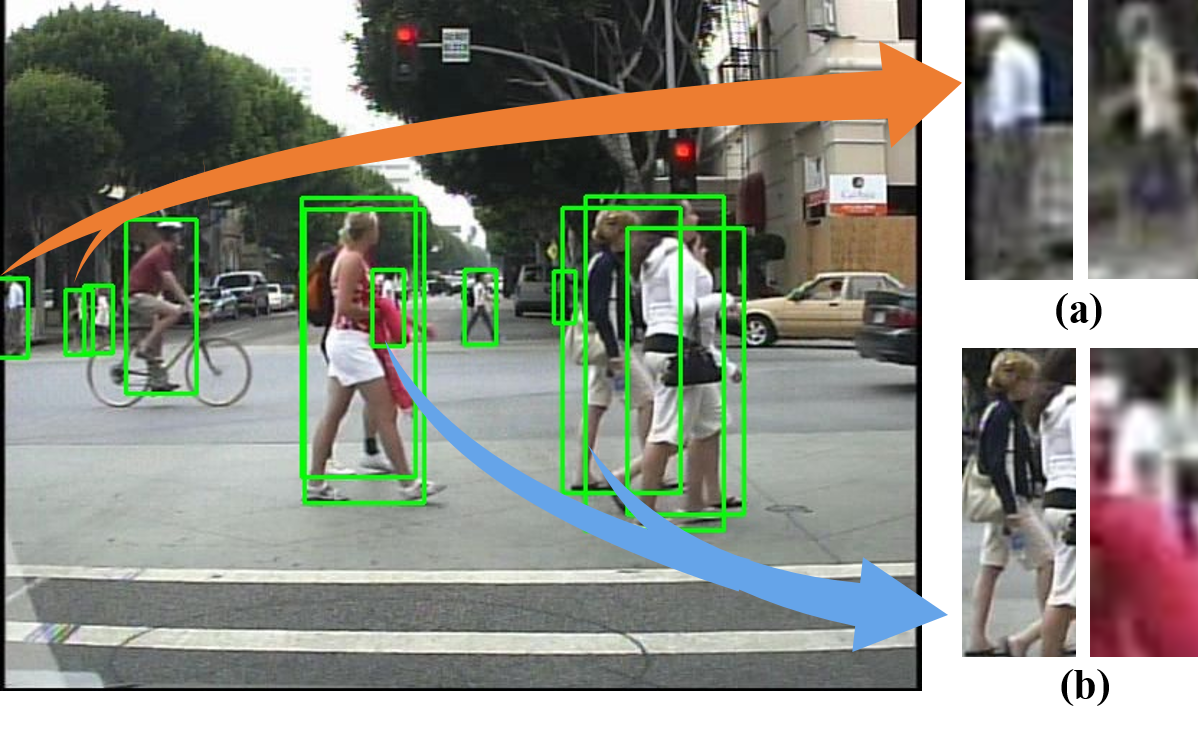
Abstract Pedestrians with challenging patterns, e.g. small scale or heavy occlusion, appear frequently in practical applications like autonomous driving, which remains tremendous obstacle to higher robustness of detectors. Although plenty of previous works have been dedicated to these problems, properly matching patterns of pedestrian and parameters of detector, i.e., constructing a detector with proper parameter sizes for certain pedestrian patterns of different complexity, has been seldom investigated intensively. Pedestrian instances are usually handled equally with the same amount of parameters, which in our opinion is inadequate for those with more difficult patterns and leads to unsatisfactory performance. Thus, we propose in this paper a novel detection approach via adaptive pattern-parameter matching. The input pedestrian patterns, especially the complex ones, are first disentangled to simpler patterns by parallel branches in Pattern Disentangling Module (PDM) with various receptive fields. Then, Gating Feature Filtering Module (GFFM) dynamically decides the spatial positions where the patterns are still not simple enough and need further disentanglement by the next-level PDM. Cooperating with these two key components, our approach can adaptively select the best matched parameter size for the input patterns according to their complexity. Moreover, to further explore the relationship between parameter sizes and their performance on the corresponding patterns, two parameter selection policies are designed: 1) extending parameter size to maximum, aiming at more difficult patterns for different occlusion types; 2) specializing parameter size by group division, aiming at complex patterns for scale variations. Extensive experiments on two popular benchmarks, Caltech and CityPersons, show that our proposed method achieves superior performance compared with other state-of-the-art methods on subsets of different scales and occlusion types.
Resources: [Paper], [Appendix], [Code&Data (Password: z6gg)]
Education
![]()
- 2020/09~NOW: Master-Doctorate Degree Program on Computer Vision. Pattern Recognition and Information Retrieval Lab (PRIR Lab), University of Science and Technology Beijing.
- 2016/09~2020/06: Bachelor Degree on Computer Science and Technology. School of Computer and Communication Engineering, University of Science and Technology Beijing.
Work Experiences
![]()
- 2021/06~2022/01: Internship on Data Algorithm Engineering at Data Platform Department, Tencent.